
STM32再认识 - (2) 异常与中断
异常与中断
本篇笔记主要是给自己看的,会省略掉我认为是常识的东西。
异常(Exception)
介绍
在 ARM 术语中,所有打破处理器执行顺序的任务都称为"异常",而中断是一种异常类型。
处理异常的程序代码片段通常称为异常处理程序(exception handlers)。它们是编译后的程序映像的一部分。
异常优先级
分为抢占优先级与子优先级:
- 抢占优先级:
决定是否能够打断正在执行的异常服务。 - 子优先级:
当有多个同一抢占优先级的异常被挂起时,决定内核先响应哪一个异常。
一般不会把优先级设计的过于复杂。因为复杂的 NVIC 会导致功耗上升。
异常的状态
| 状态 | 描述 |
|---|---|
| Inactive | The exception is not active and not pending. |
| Pending | The exception is waiting to be serviced by the processor. An interrupt request from a peripheral or from software can change the state of the corresponding interrupt to pending. |
| Active | Active An exception that is being serviced by the processor but has not completed. |
| Active and pending | The exception is being serviced by the processor and there is a pending exception from the same source. |
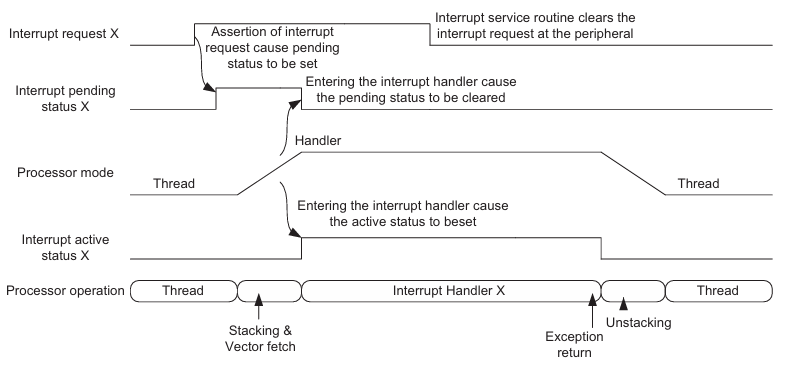
当系统正常运行时,所有异常处于 Inactive 。
若产生一个异常请求,且内核接受了该异常请求开始执行对应的异常服务程序,则称该请求 Active 。
若在异常服务程序完成前再次出现该请求,则称该异常请求 Active and pending 。
若在上一异常服务程序完成前,一个较低优先级的异常发出请求,此时内核无法响应,则称该异常 Pending 。
注意:异常的触发和异常的请求不是同步的,异常请求后由 NVIC 挂起寄存器保持异常请求,此时异常的触发源即使失能也会保持异常请求。
异常的类型
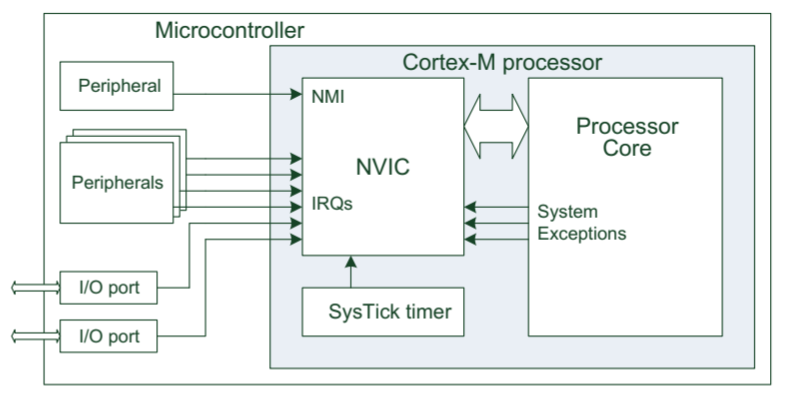
Cortex-M3 和 Cortex-M4 的嵌套向量中断控制器(Nested Vectored Interrupt Controller, NVIC) 支持多达 240 个中断请求(Interrupt Requests, IRQ)、不可屏蔽中断 (Non Maskable Interrupt, NMI)、SysTick(系统节拍)定时器中断和许多系统异常。
- 大多数 IRQ 由定时器、I/O 端口和通信接口(例如 UART、I2C)等外设生成。
- NMI 通常由看门狗定时器或欠压检测器 (BOD) 等外设生成。
- 其余的异常来自处理器核心。
- 中断也可以由软件产生(SVCall)。
Reset
复位在上电或热复位时触发。在异常模型中,Reset 被视为一种特殊形式的异常。
当 Reset 被置位时,处理器的操作可能会在指令中的任何点停止。当 Reset 无效时,将从向量表中复位条目提供的地址开始,以线程模式下的特权级执行。
NMI
不可屏蔽中断 (Non Maskable Interrupt, NMI) 可外设或软件触发。
它是除 Reset 之外的最高优先级异常。它永久启用并具有固定优先级(-2)。 NMI 不可能:
• 被任何其他异常屏蔽或阻止激活。
• 被复位以外的任何异常抢占。
HardFault
HardFault 是由于异常处理过程中的错误或由于任何其他异常机制无法管理异常而发生的异常。 HardFault 的固定优先级为 -1,这意味着它们的优先级高于任何具有可配置优先级的异常。
MemManage
MemManage 故障是由于内存保护相关故障而发生的异常。对于指令和数据存储器事务,固定存储器保护约束决定了该故障。该故障始终用于中止对从不执行 (XN) 内存区域的指令访问。
BusFault
总线故障是由于指令或数据存储器事务的存储器相关故障而发生的异常。这可能是由于在内存系统中的总线上检测到的错误造成的。
UsageFault
使用错误是由于与指令执行相关的错误而发生的异常。这包括:
- 未定义的指令
- 非法的未对齐访问
- 指令执行时的无效状态
- 异常返回时的错误。
当核心配置为报告以下情况时,以下情况可能会导致UsageFault:
- 字和半字存储器访问时的未对齐地址
- 除以零。
SVCall
主管调用 (supervisor call, SVC) 是由 SVC 指令触发的异常。在操作系统环境中,应用程序可以使用SVC指令来访问操作系统内核功能和设备驱动程序。
PendSV
PendSV 是一个中断驱动的系统级服务请求。在操作系统环境中,当没有其他异常处于活动状态时,使用 PendSV 进行上下文切换。
SysTick
SysTick 异常是系统计时器在达到零时生成的异常。软件还可以生成 SysTick 异常。在操作系统环境中,处理器可以使用此异常作为系统时钟。
Interrupt (IRQ)
中断(IRQ)是由外设发出信号或由软件请求生成的异常。所有中断都与指令执行异步。在系统中,外设使用中断与处理器进行通信。
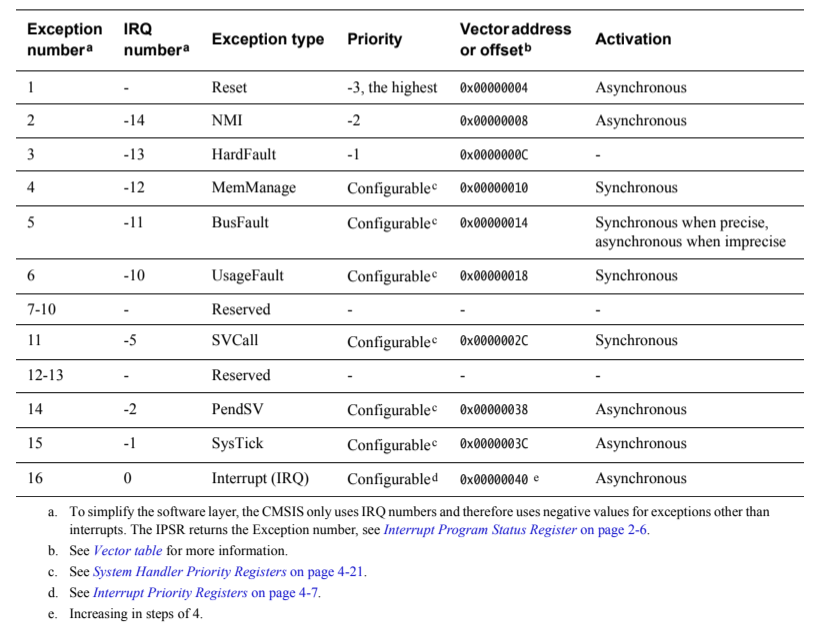
不难发现,中断号 1-15 异常都是内核异常(与内核同步);之后的异常一般由微控制器厂商设计(与内核异步)。
异常的响应(概览)
为了恢复被中断的程序,异常序列需要某种方式来存储被中断程序的状态,以便在异常处理程序完成后可以恢复。一般来说,这可以通过硬件机制或硬件和软件操作的混合来完成。
在 Cortex-M 处理器中,当接受异常时,一些寄存器会自动保存到堆栈中,并且也会在异常返回序列中自动恢复。这种机制允许将异常处理程序编写为普通 C 函数,而无需任何额外的软件开销。
异常服务
根据用途,异常服务(异常处理器)大致可分为 3 类:
- Interrupt Service Routines (ISRs)
The IRQ interrupts are the exceptions handled by ISRs. - Fault handlers
HardFault, MemManage fault, UsageFault, and BusFault are fault exceptions handled by the fault handlers. - System handlers
NMI, PendSV, SVCall, SysTick, and the fault exceptions are all system exceptions that are handled by system handlers.
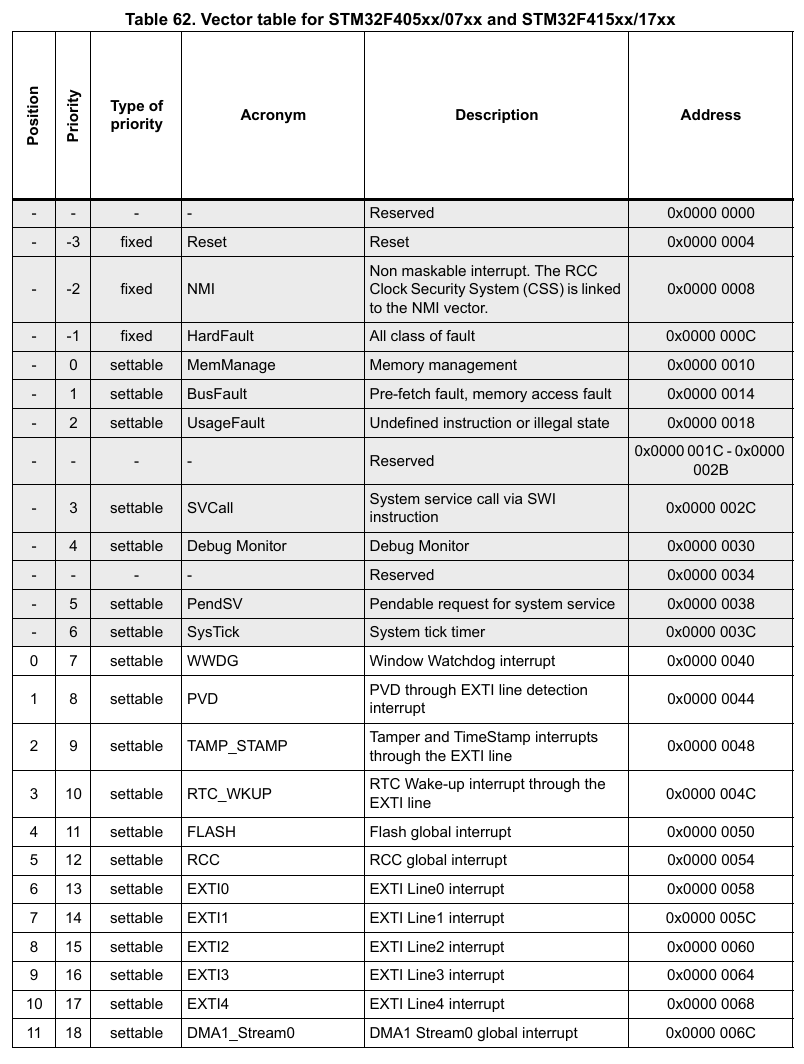
中断向量表
向量表使用
中断服务程序是线性映射的,其映射出的结构被称为中断向量表。
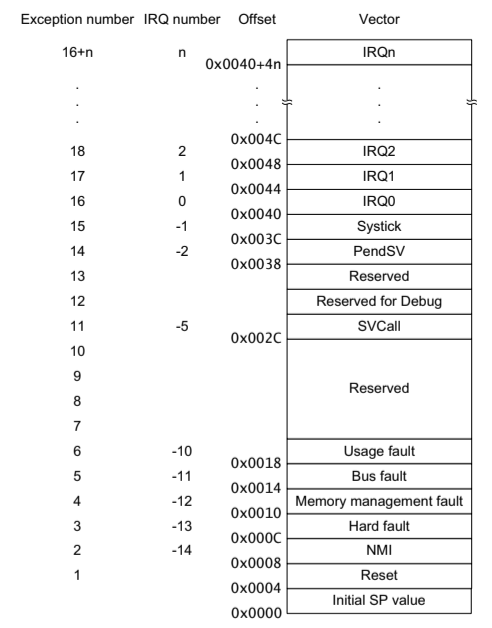
注意:每个向量的 LSB 必须设置为 1 以指示 Thumb 状态。
启动时使用的向量表还包含主堆栈指针的初始值。因为当处理器刚刚从复位状态出来并且在执行任何其他初始化步骤之前,可能会发生一些异常(例如 NMI)。
通常,起始地址(0x00000000)应该是引导存储器,并且是 ROM 介质。这导致向量表在运行时不能更改。然而,在某些应用程序中,能够在运行时修改或定义异常向量是很有用的。
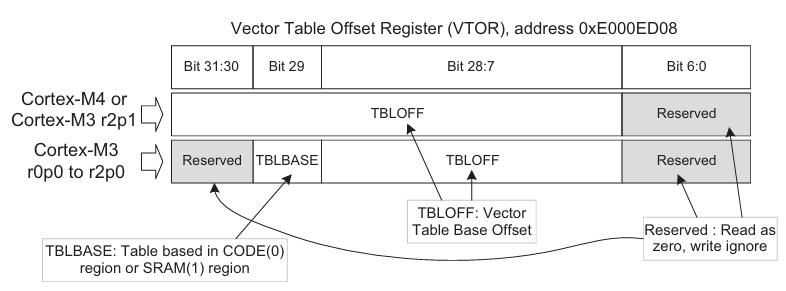
为了解决这个问题,Cortex-M3 和 Cortex-M4 处理器支持称为向量表重定位的功能。该功能提供了一个称为向量表偏移寄存器 (Vector Table Relocation, VTOR) 的可编程寄存器,用于定义用作向量表的存储器的起始地址。
VTOR 寄存器的复位值为零,并且在使用符合 CMSIS 的设备驱动程序进行应用程序编程时,可以通过“SCB->VTOR”访问该寄存器。
注意,Cortex-M3 版本 r2p0 和版本 r2p1 之间的该寄存器略有不同。在 Cortex M3 r2p0 或更早版本中,向量表只能位于 CODE 区域或 SRAM 区域,但在 Cortex-M3 r2p1 和 Cortex-M4 中删除了此限制。
一些使用重编程的例子:
-
在某些微控制器中,有多个程序存储器:boot ROM 和用户闪存。(bootloader)
- 使用 boot ROM 中的向量表进行引导
- 执行引导加载程序任务
- 将 VTOR 编程为指向用户闪存中的向量表
- 跳转到由用户闪存向量表指示的复位处理程序
-
外部加载程序。(switch 插卡带)
- 使用闪存中的向量表启动
- 初始化硬件并将外部存储的应用程序复制到 RAM
- 将 VTOR 编程为指向 SRAM 中应用程序中的向量表
- 转移到 SRAM 中向量表指示的复位处理程序并启动应用程序
-
动态修改中断向量
向量表的长度与地址
向量表的长度 必须为 。且其基地址必须是 的非负整数倍。
如果一个微控制器有 75 个 IRQ 。那么向量表的长度为 $ 75+16 \times 4 = 364 Byte \approx 0x200 Byte $, 则可用的基地址为 $ k \times 0x200 $ 。
异常的响应序列
异常响应的接受
如果满足以下条件,处理器将接受异常:
• 处理器正在运行(未停止或处于重置状态)
• 启用异常(NMI 和 HardFault 异常的特殊情况,它们始终启用)
• 异常的优先级高于当前优先级
• 异常未被异常屏蔽寄存器(例如 PRIMASK)阻止
对于 SVC 异常,如果 SVC 指令意外地在具有与 SVC 相同或更高优先级的异常处理程序中使用异常本身,它将导致 HardFault 异常处理程序执行。
异常服务的进入
一个异常入口序列包含几个操作:
- 多个寄存器的自动入栈(包括当前被选定栈的返回地址)。这使得异常处理程序可以像普通 C 函数一样编写。
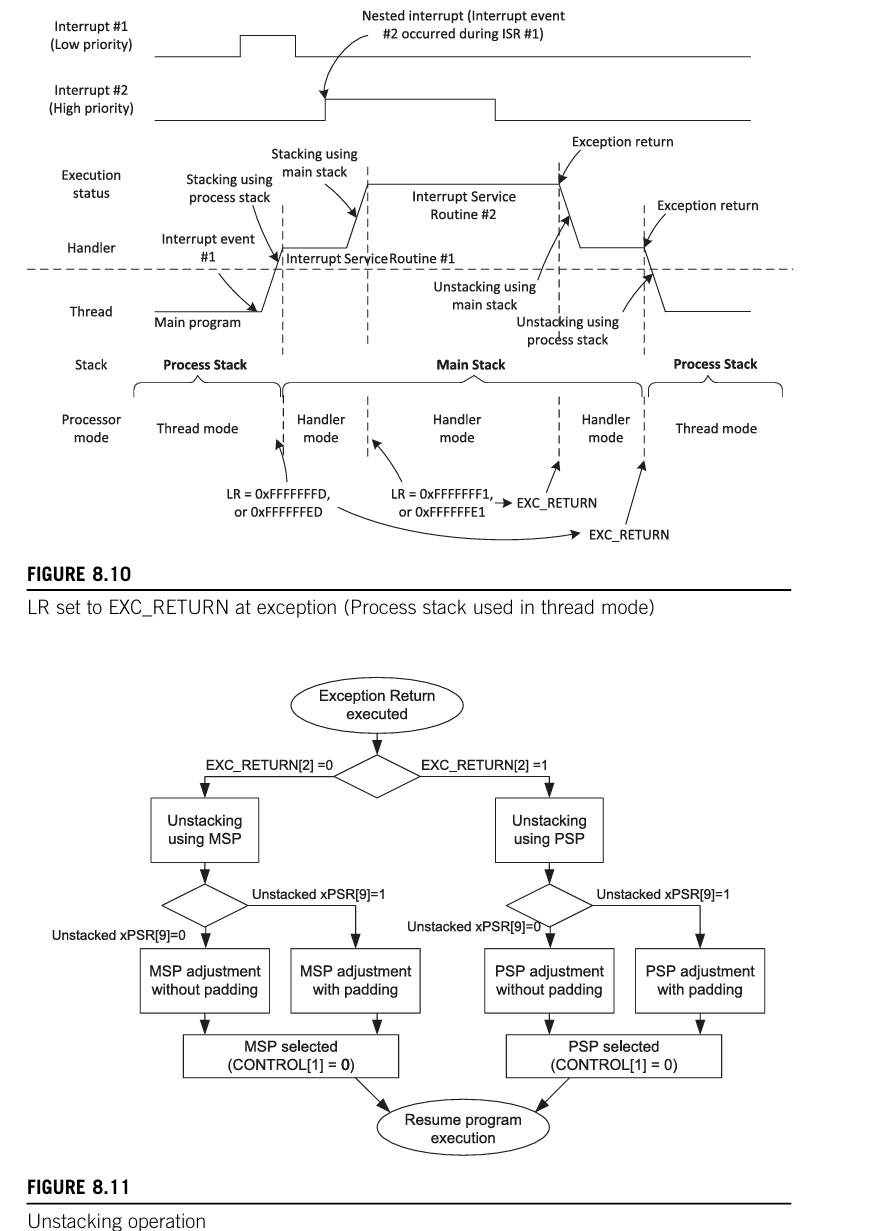
如果处理器处于线程模式并使用 PSP,则自动入栈将使用 PSP 指向的堆栈区域;否则,将自动入栈将使用 MSP 指向的堆栈区域。
-
获取异常向量(异常处理程序/ISR 的起始地址)。这可以与堆栈操作并行发生,以减少延迟。
-
获取要执行的异常处理程序的指令。确定了异常处理程序的起始地址后,就可以取出指令了。
-
各种NVIC寄存器和核心寄存器的更新。
这包括异常的挂起状态和活动状态,以及处理器内核中的寄存器,包括程序状态寄存器(PSR)、链接寄存器(LR)、程序计数器(PC)和堆栈指针(SP)。
- 根据用于堆栈的堆栈,MSP 或 PSP 值将在异常处理程序启动之前进行相应调整。
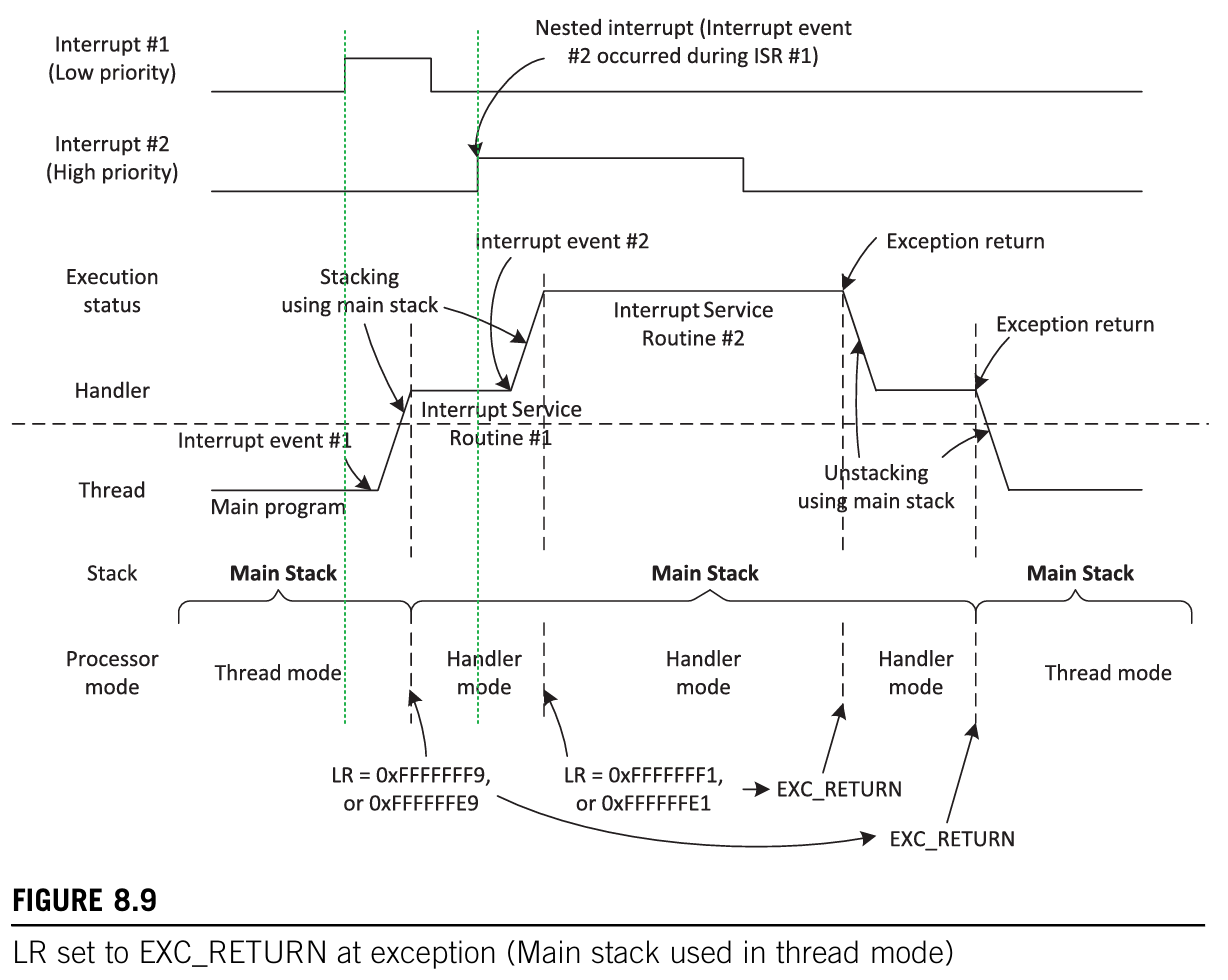
- PC 也被更新为异常处理程序的起始地址,并且链接寄存器 (LR) 被更新为一个将在异常返回中使用的的特殊值 EXC_RETURN(这是一个 32 位的值,其中高 27 位设置为 1。低 5 位中的一些用于保存有关异常序列的状态信息(例如,哪个堆栈用于入栈))。
异常处理
如果在此阶段出现更高抢占优先级的异常,则将接受新的中断,并且当前正在执行的处理程序将被挂起并被更高优先级的处理程序抢占。这种情况被称为嵌套异常。
如果在此阶段有另一个具有相同或较低抢占优先级的异常到达,则新到达的异常将保持挂起,并在当前异常处理程序完成时得到服务。
当在异常处理程序结束时,程序代码执行返回,导致 EXC_RETURN 值加载到程序计数器 (PC) 中。这会触发异常返回机制。
异常返回
在某些处理器体系结构中,使用特殊指令来返回异常,这意味着异常处理程序不能像普通 C 代码一样编写和编译。
在 ARM Cortex-M 处理器中,异常返回机制是使用称为 EXC_RETURN 的特殊返回地址触发的。
该值在异常入口处生成并存储在链接寄存器(LR)中。当使用允许的异常返回指令之一将该值写入 PC 时,它会触发异常返回序列。
在代码生成中,C 编译器将 LR 中的 EXC_RETURN 值作为普通返回地址进行处理。
由于 EXC_RETURN 机制,正常的函数是不可能返回到地址 0xF0000000 到 0xFFFFFFFF 的;但是,体系结构指定了该地址范围不得用于程序代码(Execute Never, XN),因此实际上不会造成任何混乱。
当异常返回机制被触发时,处理器在异常进入时所保存的寄存器值将被恢复,即出栈。
此外,许多NVIC寄存器(如活动状态)和处理器内核中的寄存器(PSR、SP、CONTROL)将被更新。在出栈操作的同时,处理器可以开始获取先前中断的程序的指令,以使程序尽快恢复运行。
使用 EXC_RETURN 值触发异常返回允许将异常处理程序(包括中断服务例程)编写为普通 C 函数/子例程。
在代码生成中,C 编译器将 LR 中的 EXC_RETURN 值作为普通返回地址进行处理。
由于 EXC_RETURN 机制,正常的函数是不可能返回到地址 0xF0000000 到 0xFFFFFFFF 的;但是,体系结构指定了该地址范围不得用于程序代码(Execute Never, XN),因此实际上不会造成任何混乱。
详解异常响应
在上面的叙述中,已经了解了异常触发后的大致响应过程。接下来将对异常响应中的细节进行分析。
基础概念
引理:在 C 中的异常服务函数
刚刚看了数学的整活视频,有点上头,容我 cosplay 一下数学生🤪。(【我能在 PPT 里画出所有国旗吗?(Pt. 1) | Dr. Zye】)
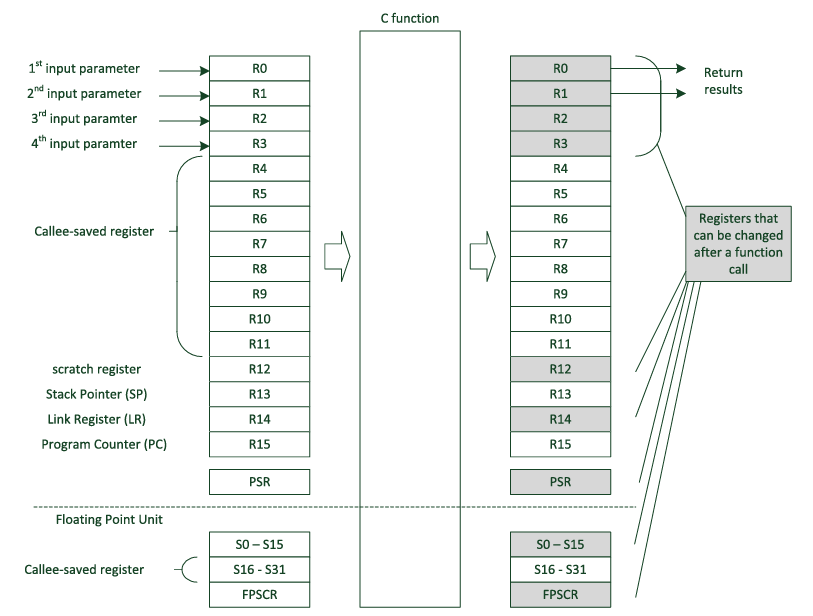
根据 《Procedure Call Standard for ARM Architecture》(原名《ARM Architecture Procedure Call Standard, AAPCS》):
The first four registers r0-r3 (a1-a4) are used to pass argument values into a subroutine and to return a result value from a function. They may also be used to hold intermediate values within a routine (but, in general, only between subroutine calls).
Register r12 (IP) may be used by a linker as a scratch register between a routine and any subroutine it calls (for details, see Use of IP by the linker). It can also be used within a routine to hold intermediate values between subroutine calls.
In some variants r11 (FP) may be used as a frame pointer in order to chain frame activation records into a linked list.The role of register r9 is platform specific. A virtual platform may assign any role to this register and must document this usage. For example, it may designate it as the static base (SB) in a position-independent data model, or it may designate it as the thread register (TR) in an environment with thread-local storage. The usage of this register may require that the value held is persistent across all calls. A virtual platform that has no need for such a special register may designate r9 as an additional callee-saved variable register, v6.
Typically, the registers r4-r8, r10 and r11 (v1-v5, v7 and v8) are used to hold the values of a routine’s local variables. Of these, only v1-v4 can be used uniformly by the whole Thumb instruction set, but the AAPCS does not require that Thumb code only use those registers.
A subroutine must preserve the contents of the registers r4-r8, r10, r11 and SP (and r9 in PCS variants that designate r9 as v6).
In all variants of the procedure call standard, registers r12-r15 have special roles. In these roles they are labeled IP, SP, LR and PC.
———— 《Procedure Call Standard for the Arm® Architecture (2025Q1)》
总之,R0~R3 用于传递变量和返回值,因此一定是被修改的,进而其现场的保存与恢复是由主调函数负责的,故对于被调函数可以自由使用;
R4~R11 用于保存函数的局部变量,在调用前后不允许发生改变。因此,若被调函数要使用,则必须进行现场的保存与恢复;
R12 被称为 Intra Procedure call scratch Register ;
剩下的应该就不用强调了。
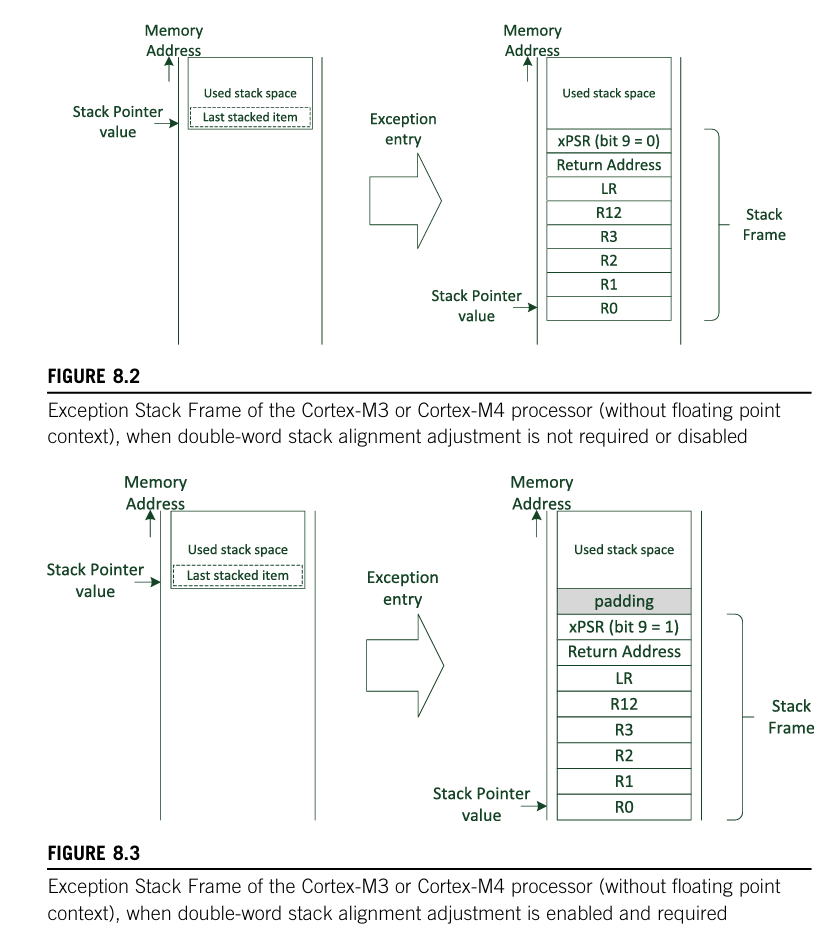
栈帧(stack frames)
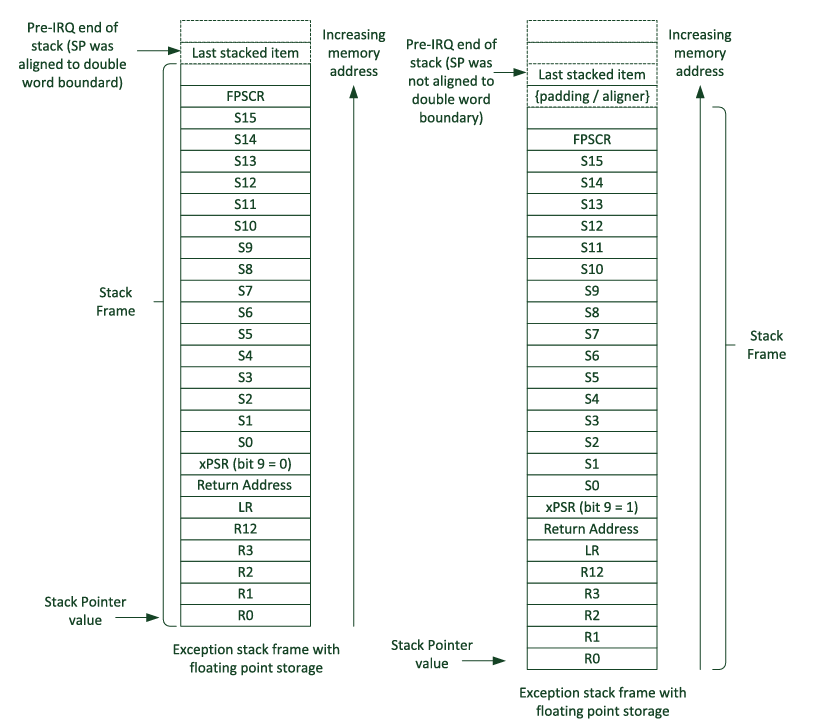
在异常进入时被压栈的数据块被称为栈帧。对于有 FPU 的芯片还需额外保存 S16~S31 。
AAPCS 的另一个要求是堆栈指针应在函数入口或出口处双字对齐。
xPSR-bit[9] 可以设置是否自动对齐堆栈指针。当被置位时, Cortex-M3 和 Cortex-M4 处理器可以自动在堆栈中插入额外的填充空间字。这样,我们就可以保证堆栈指针位于异常处理程序的开头。
带有 FPU 的微控制器的堆栈帧。
EXC_RETURN
| 31:28 | 27:5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|
| EXC_RETURNindicator | Reserved | Stack Frame Type | Returnmode | Returnstack | Reserved | Reserved |
| 0xF | 0xEFFFFF | 1 = 8words or 0 = 26words.Always 1 when the floating unit is unavailable. This value is set to the inverted value of FPCA bit in the CONTROL register when entering an exception handler. | 1(ReturntoThread) or 0(ReturntoHandler) | 1 = Return with Process Stack or 0 = Return with Main Stack |
0 | 1 |
异常序列
异常进入与压栈
Cortex-M3 和 Cortex-M4 处理器具有多个总线接口。处理器进行中断向量读取(I BUS)与堆栈操作(S BUS)同时进行,然后启动指令读取。
因此,哈佛总线架构可以减少中断延迟,因为堆栈操作和闪存访问(向量读取、指令读取)可以并行进行。如果向量表重新定位到 SRAM 或异常处理程序也存储在 SRAM 中,则可能会稍微增加中断延迟。
😲 果然如此!这下确定 SRAM 里的代码跑的慢的原因了。
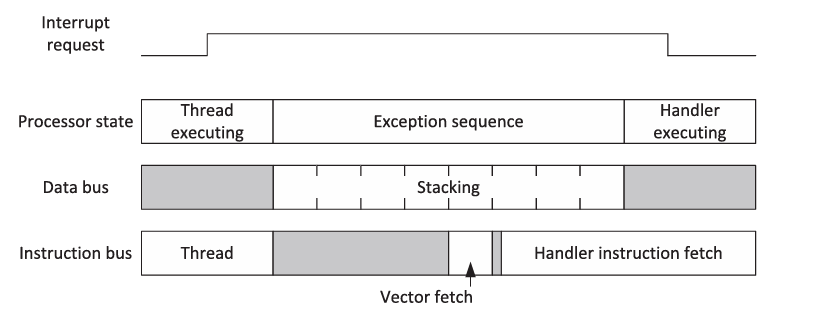
注意: 入栈顺序与堆栈帧的顺序时不一致的。例如, Cortex-M3 首先会对 PC&xPSR 寄存器进行压栈,这是为了让 PC 尽快更新为中断向量。另外由于 AHB Lite 自身的特性,数据传输落后于地址一个时钟周期。
堆栈的使用,如下图所示。
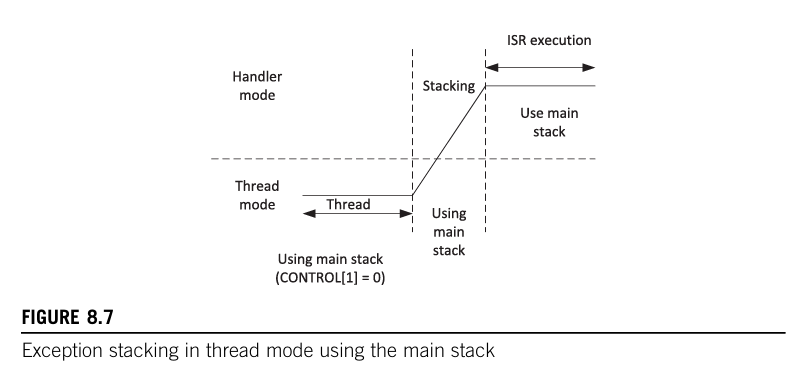
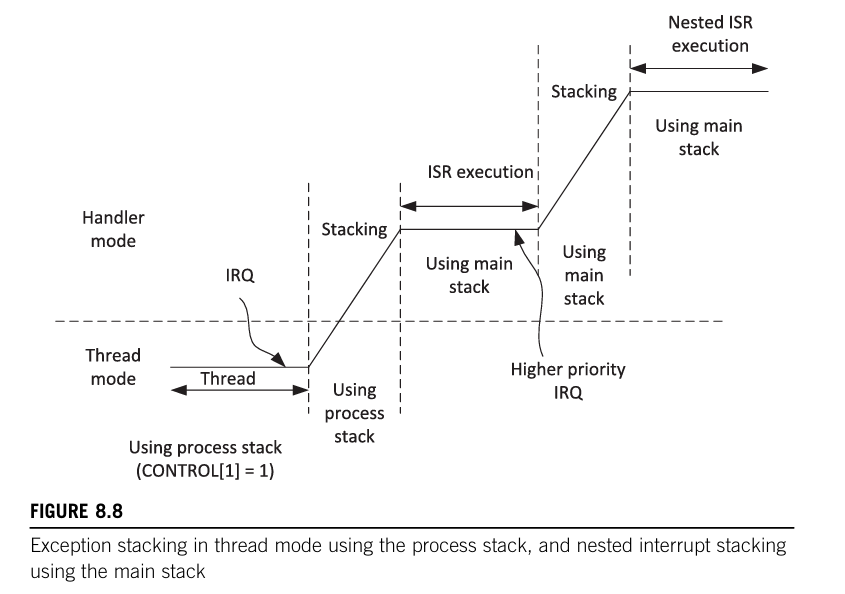
异常返回与出栈
上文基本都说过了,剩下的都在图中。
中断延迟和异常处理优化
中断延迟
术语中断延迟是指从中断请求开始到中断处理程序开始执行的延迟。
在 Cortex-M3 和 Cortex-M4 处理器中,如果内存系统是零延迟的且总线系统允许向量读取和压栈同时进行,则中断延迟仅为 12 个时钟周期(包括寄存器压栈、向量提取和中断处理程序的提取指令)。
但是,在多数情况下,因受内存系统中的等待状态的影响,延迟可能会更高。
例如,处理器正在执行内存传输,包括缓冲的写入操作,则必须在异常序列开始之前完成未完成的传输。
除了内存设备或外设生成的等待状态之外,还有其他情况可能会增加中断延迟:
- 调试器访问内存系统。
- 处理器正在以相同或更高的优先级处理另一个异常。
- 处理器正在执行未对齐的传输。从处理器的角度来看,这可能是单次访问,但在总线级别,它需要多个周期,因为总线接口需要将未对齐的传输转换为多个对齐的传输。
- 处理器正在执行位带别名写入。内部总线系统将其转换为读取-修改-写入序列,这至少需要两个周期。
多时钟周期指令的中断
有些指令需要多个时钟周期才能执行。如果在处理器正在执行多周期指令(例如整数除法)时收到中断请求,则该指令将会被放弃并在中断处理程序完成后重新启动。此行为也适用于加载双字 (LDRD) 和存储双字 (STRD) 指令。
此外,Cortex-M3 和 Cortex-M4 处理器允许在多加载和存储指令 (LDM/STM) 以及堆栈压入/弹出指令中间发生异常。
如果中断请求到达时,其中一个 LDM/STM/PUSH/POP 指令正在执行,则当前内存访问将完成,下一个寄存器编号将保存在堆栈的 xPSR(中断连续指令 [ICI] 位)中。异常处理程序完成后,多重加载/存储/推送/弹出将从传输停止的点恢复。
同样的方法适用于具有浮点单元的 Cortex-M4 处理器的浮点内存访问指令(即 VLDM、VSTM、VPUSH 和 VPOP)。
有一种特殊情况:如果被中断的多条加载/存储/推送/弹出指令是 IF-THEN (IT) 指令块的一部分,则该指令将被取消并在中断完成时重新启动。这是因为 ICI 位和 IT 执行状态位在执行程序状态寄存器 (EPSR) 中共享相同的空间。
对于具有浮点单元的 Cortex-M4 处理器,如果在处理器执行 VSQRT(浮点平方根)或 VDIV(浮点除法)时中断请求到达,则浮点指令执行与堆栈操作并行继续。
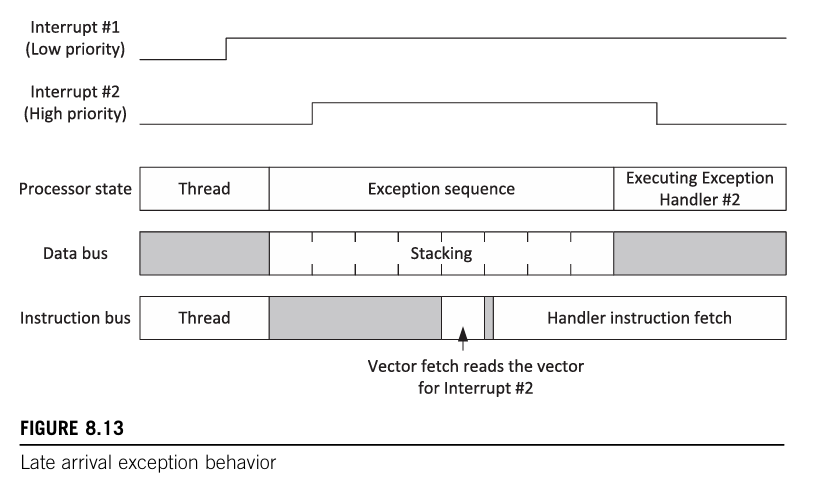
晚到(的高优先级)异常
当压栈期间出现了更高抢占优先级的异常,压栈过程不受影响,且在压栈结束后会执行优先级更高的异常处理,
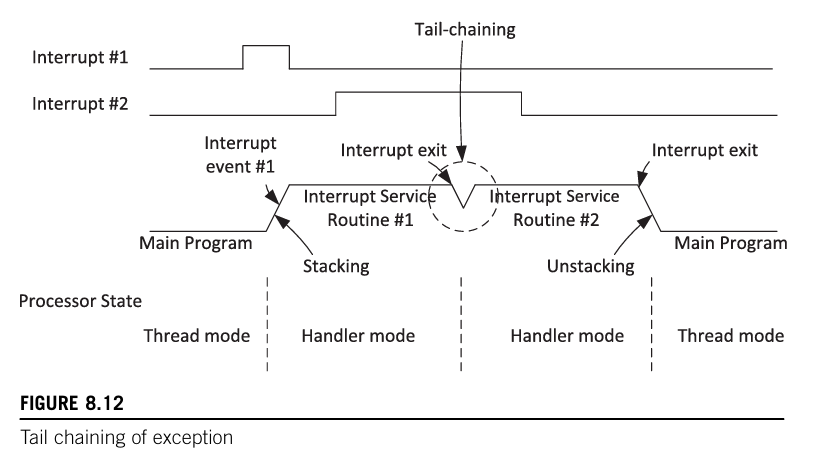
咬尾中断
当处理器完成一次异常处理时,若此时有另外一个异常被挂起,则处理器进行不会出栈与入栈操作,而是直接进行另外的异常处理。
POP 抢占
如果在另一个刚刚完成的异常处理程序的出栈过程中出现异常请求,则出栈操作将被放弃,并开始下一个异常服务的向量获取和指令获取。这种优化称为弹出抢占(Pop preemption)。
懒入栈
懒入栈是与浮点单元中的寄存器堆栈相关的功能。因此,它仅与具有浮点单元的 Cortex-M4 设备相关,没有浮点单元的 Cortex-M3 设备和 Cortex-M4 设备不需要它。
如果浮点单元被启用,则浮点单元的寄存器组中的寄存器将包含可能需要保存的数据。在上文的叙述中,如果我们为每个异常都保存浮点寄存器现场,那么每次都需要执行额外的 17 次入栈操作,这将使中断延迟从 12 个周期增加到 29 个周期。
为了减少中断延迟,Cortex-M4 处理器具有称为懒入栈的功能。默认情况下此功能已启用。当使用浮点单元(由称为 FPCA 的 CONTROL 寄存器的位 2 指示)时发生异常时,将使用较长的堆栈帧格式。
但是,这些浮点寄存器的值实际上并没有写入堆栈帧。惰性堆栈机制允许只为这些浮点寄存器保留堆栈空间,但不进行入栈操作。这种情况下,中断延迟依旧保持在12个时钟周期。
当懒入栈发生时,称为 LSPACT(Lazy Stacking Preservation Active)的内部寄存器被设置,
另一个称为浮点上下文地址寄存器(Floating Point Context Address Register)的 32 位寄存器存储浮点寄存器的保留堆栈空间的地址。
如果异常处理程序不需要任何浮点操作,则浮点寄存器在异常处理程序的整个操作过程中保持不变,并且在异常退出时不会恢复。
如果异常处理程序确实需要浮点操作,则处理器会检测到冲突并停止处理器,将浮点寄存器压入保留的堆栈空间并清除 LSPACT 。
之后,异常处理程序将恢复。这样,浮点寄存器仅在需要时才被堆叠。
懒入栈操作可能会被中断。当懒入栈期间中断请求到达时,懒入栈操作将停止并开始正常的异常堆栈。由于触发懒入栈的浮点指令尚未执行,因此中断堆栈的PC值将指向该浮点指令。
当中断服务完成时,异常返回将返回到该浮点指令,并且重新尝试该指令将再次触发惰性堆栈操作。
如果当前执行上下文(线程或处理程序)不使用浮点单元,如 FPCA 中的零值(CONTROL 寄存器的位 2)所示,则将使用较短的堆栈帧格式。